ETL — Extract, Transform, Load — is the process of pulling data from where it lives, reshaping it into something a downstream system can use, and loading it into the destination. Picture a bank that needs every branch's daily sales in one report. Extract grabs the numbers from each branch's system, Transform lines them up so dollars look like dollars and dates look like dates, and Load drops the clean result into one place a report can read. That three-step pattern is the backbone of almost every data pipeline running today.
The destination is usually a warehouse (Snowflake, BigQuery, Redshift), a database, or an analytics tool. The sources are everywhere: SaaS APIs, on-prem systems, partner SFTP endpoints (SFTP is the secure version of the old file-transfer protocol), regulatory feeds, cloud storage, and file drops from vendors that arrive on a schedule. A large share of real-world ETL is file-based: a bank's settlement extract lands as a CSV on SFTP at 3am, a health insurer's claims feed arrives as a fixed-width batch, a retailer's daily inventory drop comes in as a series of JSON files into S3. The job is to catch those files, clean them, and pass them on.
What ETL Means: Extract, Transform, Load
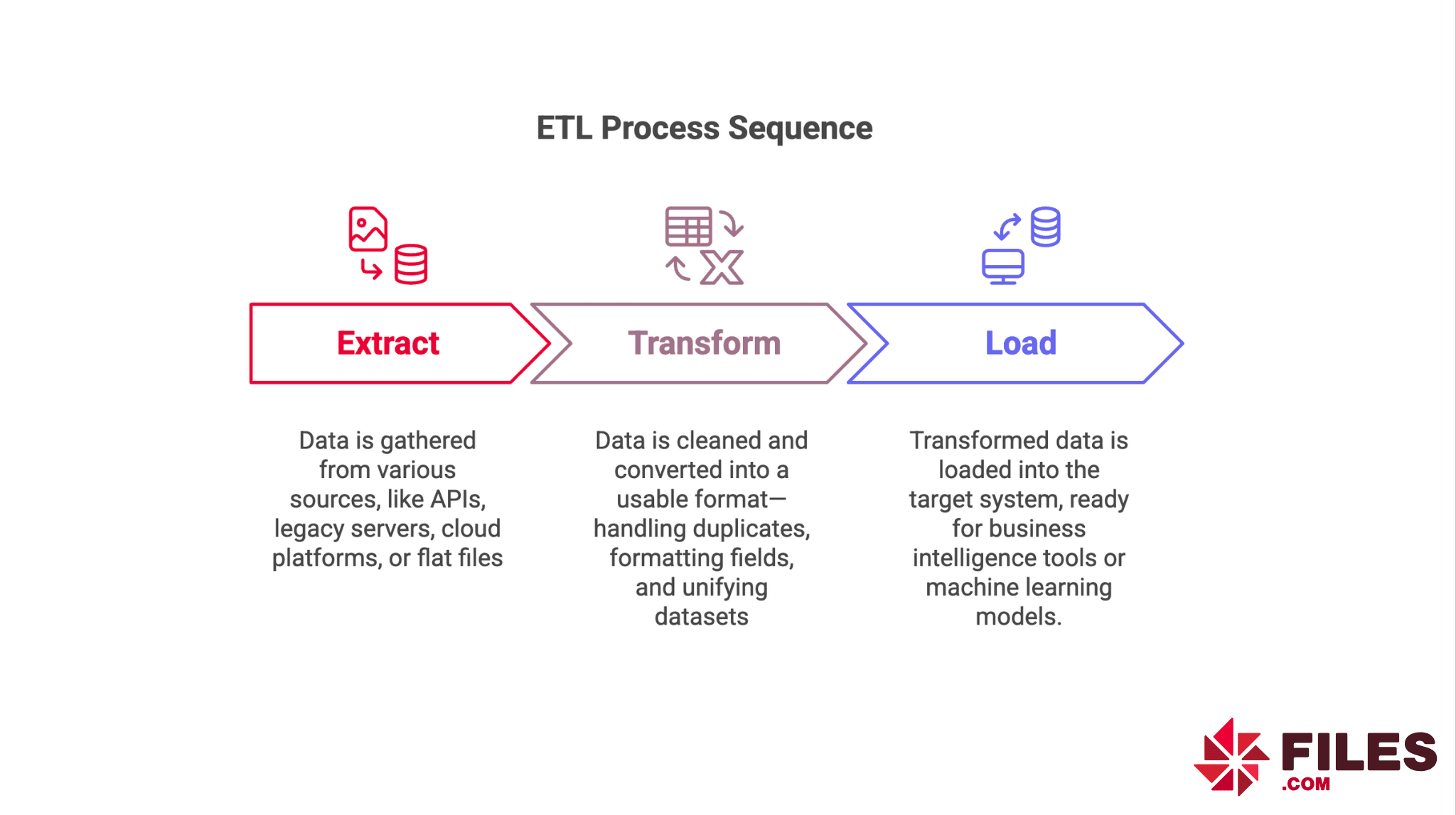
ETL stands for Extract, Transform, Load. It is a data integration process that collects raw data from many sources, cleans and formats it, then moves it into one central destination — often a database, a data warehouse, or an analytics platform. The three words name the three stages, in order.
Extract pulls data out of where it lives: an API, a legacy server, a cloud platform, or a flat file dropped on a server. At this stage you are just gathering raw material, copying it out without changing it.
Transform reshapes that raw material into something the destination can use. This is the cleanup step: removing duplicate rows, fixing inconsistent date formats, renaming fields so two systems agree on what "customer ID" means, and stitching separate datasets together.
Load writes the cleaned data into its final home, ready for a reporting tool, a dashboard, or a machine-learning model to read. Once data is loaded, the people who need answers can finally ask their questions of one tidy table instead of a dozen messy ones.
Run those three steps on a schedule and you turn scattered raw information into structured, trustworthy data — which is why ETL sits at the core of nearly every data strategy.
The Main Ways ETL Runs
ETL can run in a few different shapes, and the right one depends on how fresh the data needs to be.
Batch ETL extracts and processes data on a fixed schedule — hourly, or every night. It is the simplest and most common shape, and it fits reporting and historical analysis where waiting until the nightly run is fine.
Real-Time ETL (also called streaming ETL) moves data continuously, the moment it changes at the source. It costs more to build and run, so you reach for it when minutes matter: fraud detection, live dashboards, on-the-fly personalization.
Cloud-Native ETL is built for cloud platforms from the start. It scales up and down on demand, is driven by APIs rather than hand-managed servers, and fits hybrid and multi-cloud setups well.
ETL as a Service hands you the whole pipeline as a managed product. Someone else runs the servers and the software, so your team spends its time on data mapping and analysis instead of infrastructure.
Securing Data as It Moves Through ETL
Sensitive data spends a lot of its life in motion during ETL — leaving a source, sitting on a staging server, landing in a warehouse. Each hop is a place it could leak, so a pipeline has to be secured end to end.
Encryption protects data both while it sits on disk (at rest) and while it travels between systems (in transit). Use strong, current standards: TLS 1.2 or 1.3 for transit and AES-256 at rest.
Authentication and Access Control make sure only approved systems and people can start an ETL job or touch the sensitive data inside it. A pipeline with weak credentials is a side door into everything it touches.
Compliance Readiness means the tools in the pipeline line up with the rules your industry lives under — HIPAA in healthcare, GDPR for personal data in Europe, SOC 2 for service providers. The certification matters most in healthcare, finance, and media, where a failed audit has real cost.
Audit Trails and Logging record every transfer, every login, and every failure so you can prove what happened and spot a problem fast. When a transfer fails or a file arrives corrupted, the log is where you find out before it spreads downstream.
How ETL Powers Modern Industries
ETL is not only a big-tech tool. It quietly runs the data behind most industries.
In healthcare, ETL unifies electronic health records, billing systems, and lab results so clinicians can make decisions on a complete picture. In broadcast and media, it normalizes large video-metadata files so content can be distributed and monetized across platforms. In finance, it consolidates transaction data for fraud detection, audits, and regulatory reporting. In logistics, it pulls together IoT sensor data, supply-chain records, and order data to tune fleet performance and delivery schedules. Anywhere a team needs a clear answer out of scattered, mismatched data, ETL is doing the joining.
Choosing the Right ETL Tool
When you compare ETL tools, a handful of questions sort the good fit from the wrong one.
Integration Flexibility: Does it connect to the sources and destinations you actually use — cloud storage, SFTP endpoints, REST APIs? A tool that can't reach half your data is a non-starter.
Scalability: Will it keep up as your data volume grows, without a rebuild every time you double?
Automation and Scheduling: Can you set workflows to run on their own, with triggers, automatic retries when a step fails, and conditional logic for the "if this, then that" cases?
Security and Compliance: Is it built with real encryption, access control, and the industry certifications your auditors ask about?
Team Skillset: Some tools need deep coding; others are visual or no-code. Match the tool to the people who will run it.
The Direction ETL Is Heading
ETL keeps changing as cloud-native and real-time designs become the norm. A few shifts are already underway.
ELT (Extract, Load, Transform) flips the order: load the raw data into a powerful modern warehouse first, then transform it there, using the warehouse's own compute instead of a separate transform server.
AI-Assisted ETL uses machine learning to suggest how fields map between systems, flag anomalies in the data, and tune performance without a human watching every run.
Serverless and Event-Driven Pipelines kick off a workflow the instant something happens — a file lands, a record changes — with no always-on server to manage in between.
DataOps brings DevOps habits to the data pipeline: version control, automated testing, rollback when a change breaks something, and continuous monitoring.
Running the File Layer of Your ETL on a Modern Platform
A large fraction of ETL is still file-based, and the file layer is where pipelines quietly break — a partner's nightly drop never lands, a half-written file gets picked up before it finished uploading, or nobody can prove which file fed last quarter's numbers. Files.com is the cloud-native File Orchestration Platform: one platform that replaces the stack of legacy tools IT teams run to move files — SFTP and FTP servers, file-transfer suites, and the custom scripts holding them together. It speaks every common protocol, connects to 50+ cloud and on-prem systems, automates every transfer, and keeps a complete audit trail of who moved what and when.
For ETL specifically, think of Files.com as the Extract-Transform-Verify layer that feeds the rest of your pipeline. It extracts by catching files from any source — a partner SFTP endpoint, a vendor's S3 bucket, a regulatory feed — and can compress, decompress, encrypt, or rename them on arrival before anything downstream touches them. A file landing in a folder can trigger an automated workflow on its own, so the handoff to your warehouse loader happens without a CRON job or a missed step, and the same actions are scriptable through a full REST API and SDKs. Every transfer is logged for audits, which is the "verify" part — when last quarter's report looks wrong, the record of exactly which files arrived and when is already there.
To go a level deeper on the file-movement side of this, see how electronic data transfer works as the foundation under file-based pipelines.
To put Files.com underneath your own ETL flow, explore Files.com's transform and extract capabilities or start a free trial — no credit card, live in minutes.